註:本文同步更新在Notion!(數學公式會比較好閱讀)
自編碼器 (Autoencoder) 是一種無監督學習模型,主要用於學習數據的有效表徵或特徵。其核心思想是通過一個神經網路將輸入數據壓縮為低維隱含表示,再通過解碼器將其重構為原始數據。自編碼器經常被用於數據降維、特徵提取和去噪等任務。
自編碼器的基本結構由兩部分組成:

這意味著網絡需要學習一種壓縮和重構的能力,同時保留數據中的關鍵特徵。
自編碼器可以表示為兩個映射函數:

自編碼器的目標是使得輸入和重構之間的差異最小化,這可以通過最小化重構損失函數來實現。常用的損失函數是均方誤差(Mean Squared Error, MSE):
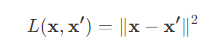
自編碼器的訓練過程與普通的神經網絡類似,通過反向傳播算法來更新編碼器和解碼器的權重。
自編碼器在數學上可以被看作是一種非線性降維技術。與主成分分析(Principal Component Analysis, PCA)等線性降維方法不同,自編碼器通過非線性激活函數可以學習數據的更複雜結構。
編碼器的過程實際上是在高維空間中找到一個低維的子空間,並學習如何將數據投影到這個子空間。這個隱含表示 z是數據的壓縮版本,具有比原始數據更少的維度。

這裡的核心思想是學習數據中的重要特徵,並用少量的隱含單元來表示這些特徵。
根據不同的需求,自編碼器有多種變體,每種變體針對不同的應用場景和數據性質。
儘管自編碼器在學習數據表示和降維方面具有優勢,但其訓練過程中的非凸性問題可能導致訓練過程中出現局部最優解。此外,隱含層維度的選擇也至關重要,過少的隱含單元會導致信息丟失,而過多的單元會導致模型的重構能力過強,從而難以捕捉數據中的核心結構。

